Awesome Rails search with Solr and Sunspot
Mat Brown
Pivotal Labs Tech Talks
16 March 2010
The Road to Victory
- Get up and running with Sunspot::Rails — it's easy!
- How Solr works
- Exploring Sunspot and Solr's search features
- Sunspot in production
Let's get started!
Install Sunspot
Install the gem(s):
# gem install sunspot-railsGenerate the config file:
$ script/generate sunspotStart Solr
$ rake sunspot:solr:startThis creates some files and directories in your Rails root:
solr/conf/solrconfig.xml
solr/conf/schema.xml
solr/data/You can edit the XML files to customize Solr's behavior.
Index your data
Make your model searchable:
class Post < ActiveRecord::Base
searchable do
text :title, :body
end
endAdd your data to Solr:
$ rake sunspot:reindexYou only need to do that once.
Add search to your app
Create a controller action:
class PostsController < ApplicationController
def search
@search = Post.search do
keywords(params[:q])
end
end
endAdd search to your app
Output your results:
.results
- @search.results.each do |post|
.result
%h1= h(post.title)
%p= h(truncate(post.body))
.pagination= will_paginate(@search.results)That was easy.
So what is this Solr thing?
Solr is a standalone HTTP server that provides a document-oriented, inverted index of fulltext and scalar data.
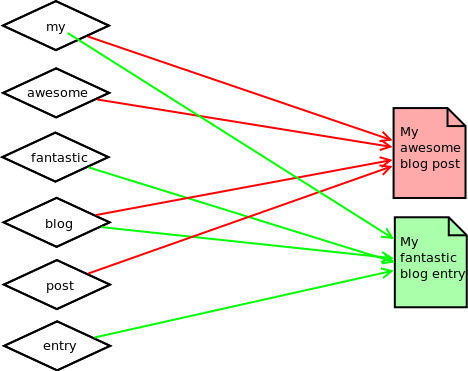
This is an inverted index.
Why is Solr awesome?
- Data is indexed by your application, how you want, when you want.
- Standalone web service provides multiple good paths to scaling.
- Wildly popular and maintained by the Apache Software Foundation.
What kind of data can Solr index?
- Fulltext
-
Scalar types
- String
- Integer
- Float
- Time
- Boolean
- Trie Fields
Attribute Fields in Sunspot
class Post < ActiveRecord::Base
belongs_to :blog
has_and_belongs_to_many :categories
searchable do
integer :blog_id
integer :category_ids, :multiple => true
time :published_at, :trie => true
end
endAttribute Field Scoping
Match a value exactly:
with(:blog_id, 1)Attribute Field Scoping
Match by inequality:
with(:published_at).less_than(Time.now)Attribute Field Scoping
Match by multiple values:
with(:category_ids).any_of([1, 3, 5])Attribute Field Scoping
Match with a range:
with(:published_at).between(
Time.parse('2010-01-01')..Time.parse('2010-02-01')
)Attribute Field Scoping
Combine restrictions with connectives:
any_of do
with(:expired_at).greater_than(Time.now)
with(:expired_at, nil)
endAttribute Field Scoping
Exclude specific instances from results:
without(current_post)Drilling Down
Drill-down search: The Problem
- The user has performed a keyword search.
- We want to allow them to drill down by category.
- However, we only want to show categories which will return results given the keywords they've entered.
Facets: The Solution
Post.search do
keywords params[:q]
with :category_ids, params[:category_id] if category_id
facet :category_ids
endFacets: The Solution
- @search.facet(:category_ids).rows.each do |row|
- category_id, count = row.value, row.count
- category = Category.find(category_id)
- params_with_facet = params.merge(:category_id => category_id)
.facet
= link_to(category.name, params_with_facet)
== (#{count})
But that's not very efficient!?
Instantiated Facets
class Post < ActiveRecord::Base
has_and_belongs_to_many :categories
searchable do
integer :category_ids,
:multiple => true,
:references => Category
end
endNow Sunspot knows that :category_id is a reference to Category objects.
Instantiated Facets
- @search.facet(:category_ids).rows.each do |row|
- category, count = row.instance, row.count
- params_with_facet = params.merge(:category_id => category.id)
.facet
= link_to(category.name, params_with_facet)
== (#{count})
The first time you call row.instance on any row, Sunspot
will eager-load all of the Category objects referenced by the
facet rows.
But what if I've already selected a category? Can't I have more?
- The user has already selected a category.
- Most posts only have one or two categories.
- So, the only categories returned by the facet are the ones that are cross-assigned to posts in the selected category.
- We'd really like to be able to select more than one category.
But what if I've already selected a category? Can't I have more?
- The user has already selected a category.
- Most posts only have one or two categories.
- So, the only categories returned by the facet are the ones that are cross-assigned to posts in the selected category.
- We'd really like to be able to select more than one category.
- No problem.
Multiselect Faceting
- For the purposes of computing the category facet, we want to ignore the fact that a category has already been selected.
- But we want to take into account all of the other selections the user has made.
- Enter Multiselect Faceting, a new feature in Solr 1.4.
Multiselect Faceting
Post.search do
keywords params[:q]
if params[:category_ids]
category_filter =
with :category_ids, params[:category_ids]
end
facet :category_ids, :exclude => category_filter
endTuning Fulltext Relevance
Returning the most relevant results for a keyword search is crucial. Here's what we'd like to do:
- Keyword matches in the
titlefield are more important than matches in thebodyfield. - If the exact search phrase is present in the title, consider that highly relevant.
- Posts published in the last 2 weeks are considered more relevant.
Tuning Fulltext Relevance: Field Boost
Post.search do
keywords params[:q] do
boost_fields :title => 2.0
end
endKeyword matches in the title field are twice as relevant as keyword matches in the body field.
Tuning Fulltext Relevance: Phrase Fields
Post.search do
keywords params[:q] do
phrase_fields :title => 5.0
end
endIf the search phrase is found exactly in a post's title field, that post is 5 times more important than it would be otherwise.
Tuning Fulltext Relevance: Boost Queries
Post.search do
keywords params[:q] do
boost(2.0) do
with(:published_at).greater_than(2.weeks.ago)
end
end
endPosts published in the last two weeks are twice as relevant as older posts.
Solr in Production
Running Solr in Production
-
Don't:
- use Sunspot's embedded Solr instance.
- use package-managed Tomcat/Jetty/Solr packages.
-
Do:
- set up and maintain your own Solr instance.
- give Solr its own machine.
- use this tutorial: http://wiki.apache.org/solr/SolrTomcat
Running Solr in Production
When you first install Solr:
$ sunspot-installer -fv /path/to/my/solr/instance/homeWhen you upgrade Sunspot:
$ sunspot-installer -v /path/to/my/solr/instance/homeCommit Frequency
What happens when you index or delete a document:
- Solr stages your changes in memory.
- It's fast and inexpensive.
- But the changes aren't yet reflected in search results.
Commit Frequency
What happens when you commit the index:
- Solr writes all of the changes since the last commit to disk.
- Solr's active Searcher instance is deprecated, and will not service new search requests.
- Solr instantiates a new Searcher, which reads the updated index from disk into memory.
- Then it auto-warms your caches.
- Then it's ready to respond to search requests.
- It's slow and expensive.
How not to commit too much
- By default, Sunspot::Rails commits at the end of every request that updates the Solr index. Turn that off.
- Use Solr's
autoCommitfunctionality. That's configured insolr/conf/solrconfig.xml - Be glad for assumed inconsistency. Don't use search where results need to be up-to-the-second.
Scaling Solr
- Operating System Resources
- Caching
- Replication
- Sharding
Scaling Solr: Operating System Resources
- Solr's memory needs will grow in proportion to your index size.
- Make sure Solr's heap size is sufficient to hold your index.
Scaling Solr: Caching
- Filter Cache: Cache the set of documents matching a particular filter. Each filter is cached independently for reuse in subsequent searches.
- Query Result Cache: Cache the results of a particular query, in order.
- Document Cache: Cache stored fields for a given document.
When a new Searcher is instantiated (after a commit), the caches are autowarmed, meaning that they are pre-populated with data from the new index. This reduces cache misses but means that starting up a searcher takes longer. You can configure how much autowarming you want.
Scaling Solr: Replication
- Standard master/slave architecture.
- Scales with the frequency of search traffic.
- All master/slave communication done over HTTP.
- Slave instance(s) poll master at a configured interval.
- If the master index has been committed since the last poll, slaves receive the changes.
- Sunspot supports a master/slave configuration using the
MasterSlaveSessionProxy. - If you're using more than one slave, put a load balancer in front of them.
Scaling Solr: Sharding
- Index is divided according to natural criteria (data type, geography, etc).
- Scales with the size of your index.
- Writes go to a single shard instance based on those criteria.
- Searches go to an single instance, which then aggregates the results from all the shards.
- Sunspot gives you a starting point for this using the
ShardingSessionProxy, which you subclass to implement the business logic for determining shards.
That is all.
Questions?
More Info
- Sunspot Home Page: http://outoftime.github.com/sunspot
- Sunspot Wiki: http://wiki.github.com/outoftime/sunspot
- Sunspot API Docs: http://outoftime.github.com/sunspot/docs
- Sunspot::Rails API Docs: http://outoftime.github.com/sunspot/rails/docs
- Solr Wiki: http://wiki.apache.org/solr
- Sunspot IRC Channel: #sunspot-ruby @ Freenode
- Sunspot mailing list: ruby-sunspot@googlegroups.com